고정 헤더 영역
상세 컨텐츠
본문
반응형
What is AI? • Thanks to the development of deep learning, almost all areas of AI have advanced dramatically.
Sub-fields of AI • Perception • Computer vision – image classification, object recognition, robotic perception, machine vision …
• Speech recognition
• Natural language processing
• Machine translation, information extraction, question answering, information retrieval, …
• Planning and decision making
• Robotics
• Many other sub-fields
AI, ML, DL
Artificial Intelligence > Machine Learning > Deep Learning
AI 1950’s
ML 1980’s
DL 2010’s
Taxonomy of Machine Learning 1. 지도학습 (Supervised Learning)
지도학습은 입력(input)과 그에 해당하는 출력(output) 쌍으로 구성된 학습 데이터를 사용합니다. 학습 과정에서 모델은 주어진 입력으로부터 출력을 예측하는 방법을 배우며, 목표는 모델이 새로운 입력에 대해 정확한 출력을 예측하도록 하는 것입니다. 주요 예시로는 이메일 스팸 분류, 은행의 고객 신용도 평가 등이 있습니다.
2. 비지도 학습 (Unsupervised Learning)
비지도 학습은 레이블이 지정되지 않은 데이터를 사용합니다. 즉, 출력 없이 입력 데이터만을 가지고 작업을 수행합니다. 이 방법은 데이터 내 숨겨진 패턴이나 구조를 발견하는데 주로 사용됩니다. 클러스터링(clustering)과 차원 축소(dimensionality reduction)가 대표적인 예로, 시장 세분화나 대규모 데이터 시각화에 활용됩니다.
3. 강화학습 (Reinforcement Learning)
강화학습은 에이전트(agent)가 환경과 상호작용하면서 보상(reward)을 최대화하는 방법을 배우는 프로세스입니다. 에이전트는 행동(action)을 취할 때마다 환경으로부터 보상을 받으며, 이 보상을 기반으로 더 나은 행동 결정을 위한 정책(policy)을 개선해 나갑니다. 비디오 게임 AI 개발이나 로봇 제어 같은 분야에서 주로 사용됩니다.
이러한 학습 방법들은 각기 다른 유형의 문제와 데이터에 적합하며, 인공지능의 성능과 효율성을 극대화하기 위해 적절히 선택되어 사용됩니다. AI 시스템을 설계할 때, 이러한 다양한 학습 방식의 이해는 필수적입니다.
CNN
Convolution Neural Network
AI 아키텍쳐 입니다.
Convolution 이라는 개념을 가지고 있습니다.
Computer vision Task 에서 입력 된 이미지를 Feature map 으로 만듭니다.
Convolution은 Filter , Kenel 이라 작은 Matix 로 만드는 작업을하는데
일반적으로 입력 image는 NxN x chanel 수로 나뉘고 RGB 채널로 3개의 채널로 나뉘어집니다.
피쳐맵중에 Fully-connected Layer 라 는 개념이있습니다.
피쳐맵이 모든 정보를 가지고 있는 feature map 입니다.
그러나 Fully-connected Layer는 모든 정보를 가지고 있기 때문에 새로운 입력 이미지가 들어올대마다 새로 만들어야하는 문제가 있습니다.
그리고 연산속도가 느리며, 학습시 잘되지 않는 문제를 가지고 있습니다.
그래서 Convloution 이라는 연산을 통해 피쳐맵을 Channel wise 하여 작은 사이즈의 Feature 맵을 만들기위해 훈련 합니다.
작은사이즈의 Feature맵을 만들 게되면 Feature 맵이 바라보는 영역시 더 넓어지는 장점을 가지게 됩니다
Convolution 하기위해선 입력 채널수와, featre맵 channel 이 같아야만 Conv할수 있습니다.
convolution을 하게되면
featuremap channel
fieaturemap width, height
- Stride
- 피쳐맵의 사이즈를 줄이는데 conv 연산시 일정 간격만큼 넘어가여 feature 맵을 만듭니다. stride 작업을 하면 feature맵이 작아지는 효과가 있습니다.
- padding
- 입력 이미지와 feature맵의 사이즈를 동일하게 해야할때 padding값을 줘서 입력이미지와 feature맵을 동일하게 만드는데 사용합니다,
maxpooling 기법
- kenel 에 최대값을 선택하는 겁니다. , minpooling , average pooling 이 있습니다
ReLU
Deep neural network 에서 backpropagration( 역전파 ) 시 값이 너무 작아지는 문제가 있었습니다.
기존엔 sigmoid 를 사용하였는데 0.25 즉 계속 미분 하게되면 0에 가까워져 Training 이 잘되지 않는 문제를 발생하여
ReLU Atctivation 을 이용해 해결 하였습니다. Relu = d / dx
Drop out
Dropoup이 나오게된건 input image가 너무 훈련된 내용 에대해서만 답을 내놓는 문제를 발생하게 됩니다
예를들어
같은 고양이 사진은 Classification 하나, 고양이가 뚱뚱하거나 , 훈련에없는 색을 가진 고양이 를 가져오면 고양이로 인식하지못하는문제를 발생하게 됩니다.
그래서 훈련할때 이미지를 가려 훈련시키는방법이 Dropout 방법입니다.
Normalization 에서 Batch-normalization 방법이 사용되는데
Feature Map이 Vanishing Gradient , Exploding Gradient를 방지하기 위해 사용합니다
- Group Batch-normalization
- Instance Batch-normalization
- Batch-normalization
- Layer Normalization
방법이 존재합니다
Stochastic Gradient Descent
모든 트레이닝 데이터가 동일한 batch 사이즈로 하는건 메모리적, 훈련으로좋지않아
Traing 데이터에 Weight 즉 연관성이 높은 부분을 줘서 Min-batch로 쪼개어 Weight로 더 훈련되도록 하는방법
CNN Optimiz
- Adam 입니다.
Softmax 정말 중요합니다.
ReLu로 연산된걸 이제 확률 분포도를 계산할때softmax를사용합니다.
Fomula 는 다음과 같습니다.
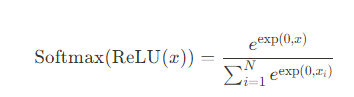
LesNet-5 1988년 최초로 CNN이 적용된 기술인데
2012년 실제 적용된 AlexNet 이 나오게 됩니다.
20년 넘게나오지 못한 이유는 다음과 같다.
- 알고리즘의 부족 ( Dropout, Batch-normalization Etc.. )
- GPGPU 환경 부족
- 트레이닝 되는 데이터 부족
- 부족한 컴퓨팅 환경 및 훈련시간
AlexNET 2012’s
- 5 convolution 3fully-connected layer
- dropout
- ReLU Actvation
- GPU trainning GTX580
VGGNET 2014
- 16-19 Very deep
- 2nd 2014 imageNet Challenge
- 3x3 conv
Inception / GoogLeNet
- 1nd 2014 imageNet Challenge
- 1x1 conv
ResNet 2015
- VGG
- 152 Layer
DenseNet 2015
- Concat + ResNet
SeNet 2018
- 2017’s ImageNet 1st
- Squeez information , Global average Pooling→ Hx W → 1x1 Conv
EfficientNet 2019
- NAS Neural Architecture Search Aproachi
최적의 아키텍쳐를 찾는 어프로치로 , Width, Depth, Resolution
ViT 2021
Vision Transformer
NLP 문제에서 transformer 를 CNN과 사용한 Aproachi
Image → CNN후
Swin Transformer 2021
Computer Vision Task
- Semantric Segmantation
- Object Detection
- Instance Segmentation
- Pose Estimation
- Traking
Semantic Segmantion
Single Object
Multi object
Semantic Segmantation
→ 이미지를 Pixel Level로 만드는것
입력이미지 → CNN → Prediction 한 이미지와 Truth ground 와 Cross Entropy 함.
IoU 계념이 나오는데
IoU는 로스를 줄이기 위해 전체 영역에서 교차되는 지점을 나눈 것을 뜻함

U-Net 2015’
- Encoder - decoder
- Encoder 에서 3x3 Conv , 2x2 max polling , feature map size를가지고
- Decoder 에선 featuremap을 확장하여 큰 Feature맵으로 만들어 감.
- Skip-architecture에선 잘려진 feature 맵을 합치는 과정을 가지게 됩니다.
Deep lab
google 에서 만들었고,
많은 도메인에서 사용함
Key
- Atrous Convolution
- Feature맵 사이즈를 작게 만들고
- ASPP
- Atous Spatioal Pyramid Pooling 라 하여
- Rate 값을 다르게 Branch 하여 병렬적으로 실행하고 합치는
- DW Convolution
- Parameter 수를 줄이게 됩니다.
- Depth Wise Sperable Convolution

object Detection
→ 싱글 객체에대해 객체의 식별, 어디에 위치하는지 알고자하는데
전통적인 방법에선
학습하기전
이미지를 추상화된 특징만들고 → 분류 된 부분을 학습했다.
그러나 이방법은 위치나 스케일이 변하면 Classification 문제를 야기하는데
이걸 해결하기위해
Sliding Window 를 사용하게 된다
이미지를 피라미드로 쌓아 붙이고 매칭되는 이미지를 슬라딩하여 객체의 위치를 식별하는 행위.
R-CNN 2013’s
2000개의 입력 피쳐를 모아 픽셀 근처 픽셀을 뭉게 CNN으로 사용했습니다.
SVM [Support Vector Machine ]
매번 새로운 이미지 가 생기면 매번 2000개를 계산하는건 문제가 되어
Fast R-CNN
CNN에선 1회만 필요로 하게 ConvNet은 한번만
ROI , Sective Search
Faster R-CNN
RPN (Region Proposal Network)를 활용 하여 R-CNN보다 250배 빠르게
YOLO
2016’s
You Only Look Once
Feature map NxN grid 로 각셀마다 입력 박스를 만든다.
그리고 두 Boundary 박스를 예측 하여 해당 부분에 객체 가 인접한지
- 하지만 이방법은 너무나 많은 박스를 만드는 문제가 있었다.
- → 이것 MSE/IoU Softmax 하여 loss를 계산하고, 중복 박스를 제거는 방법을 사용.
Single Shot Detector
→ 커다란 피쳐맵에 대해서도 예측할수 있는 SSD 입니다.
98 → 8078 개박스를 만듬
정확 속도를 증가시킴.
DETR
2020’s
Detection + Transformer 를 활용함
End-to-End Object Detction Facebook AI
Hungarian Algorithm을 사용.
Encoder 에선 Self Attention 을 사용하여 객체를 분리 했다.
Decoder 는 종단에 집중하여 머리, 다리 에 더 집중했다.
Instance Segmantation 은
pixel wise 하여 Masking 처리 하여 객체마다 식별이 가능합니다.
Mask R-CNN
객체를 마스킹한다던가
Pose Estimation
객체의 점을 선으로 연결한다던가
Tracking
VOT , MOT 로 구분된다.
Visual Object Tracking
- 하나 의 객체 T시점과 T+1 유사성을 계산
Multi Object Tracking
- 여러 객체의 T 시점과 T+1 시점의 거리변화를 계산
Reinforcement Learning
강화 학습으로
주체가 되는건 Agent’s
Environment → Observation → Agent’s → Action
Environment → Reward → Agen’s
보상은 현재는 좋지 않은지 모르지만 미래 누적 보상이 최대가 되도록 하는것
좋은 결과의 액션엔 + 점수 시그널
나쁜 결과의 액션엔 - 점수 시그널
History State
→ 현재 State가 있다면 Next State를 알수있다.
Markov State
Fully Observable Environment
→ 모든 정보 Agent’s 가 접근하여 확인할수있음
Agent state = Env State = information state
⇒ Markov Decision process [ MDP]
Partially observable Environment
→ Agents 는 Envionment 에 접근하지 못하며, 현재의 Agent state 와 Env State와 같지 않다
POMDP ( Partially Observable Markov Decision Process)
RL Componets
Policy - agents 행동
Model - 다음 액션을 하였을때 확률들
Value - 액션에 대한 보상의 좋은 정도
Category
→ model base = model / Value funciton / or / Policy
→ Model Free = Value Function / or / Policy
→ Actor Critic = Value Funciton / Policy
→ Policy base = Poliy
→ value Baes = Value function
Reinforcement Learning
- 환경에 대해 아무것도 모를때
- Agents 와 Env 인터랙션하여 하 할때
Planning
- 모든 정보를 알고 ㅇ있을대
Exploration
- 알고있는 정보중 최대 누적 보상
Explolation
- 새로운 누적 보상을 얻기위해도전
Q-Learning
- Q-table
- Q Function
E-greedy
- 일정 확률 랜덤하게 Explolation 하여 누적보상치 최대로 함
DQN
Deep Neural Network + Q-learning
Q-table , Q-function ⇒ DQN 사용
실험정보를 다시 Replay Buffer에 넣고
Target Network 를 하여
Moving Target 을 해결
Soft update 하여 더 느슨하게 업데이트 하도록
Overestmation 방지하기위해 Double DQN 사용.
Policy Gradient
→ Error 와 로스를 줄이기 위해 사용
Actor Critit
Policy Gradient 를 사용하면 들쑥날쑥한 데이터가 나오는걸 해결하기 위해 사용했고
Imitaiton learning
→ 강화 학습이 아님
따라하여 만드는것.
NLP
Natrual Language Process
RNN Recurrent Neural Network
speech recognition
-Transformer
-LLM Large Language Models;
N-gram → RNN → transformer
RNN
Sequence Data → RNN → Sequence Data
Loop back → hidden state
현재 Neural Network 에서 처리한 정보를 다음 Neural Network에 전달 함.
- Vanilla Neural NetworkSimple 한 구조
- One To one
One To Many
하나의 입력 → Many ( sequnce Data)
Image Captioning
Many To one
Action
RNN
ㄷ
hidden state
→ NN이 끝나고 다음 Neural 에게 끝난 상태정보를 전달.
→ 매번 Update 되는 문제가 있어 Backpropagation [역전파] 시 이전 값을 알수 없는문제가 있음.
LSTM ( long short term memory)
- RNN Gradient Flow폭발하거나→ Vanishing Gradient⇒ RNN 구조를 변경하거나
- cell state : hidden state 처럼 전달, 매번 UPdate 되지 않는다.
- 너무 작거나
- ⇒ Clipping , 데이터를 일부 잘라서 해결
- → Exploding Gradient
f : forget gate 얼마만큼 지울지
i: input gate 얼마만큼 입력할지
g : gate gate 새로운 셀에
o: output gate
반응형




